Product Data Readiness Audit
Cinderhaven Provisions · May 2026
Part 1: The Money
By the end of 2027, every barcode in American retail will change. GS1 Sunrise 2027 transitions the industry from linear barcodes to 2D barcodes built on GS1 Digital Link: a QR code whose foundation is a valid GTIN. Not a GTIN that looks right to a human eye. A GTIN that passes algorithmic validation. Nine of Cinderhaven’s 90 SKUs carry GTINs that do not pass. Those nine SKUs cannot participate in the transition until someone corrects a single digit in each record.
Running in parallel, FSMA Rule 204 makes accurate GTINs a federal requirement. FDA food traceability mandates them as the product identifier backbone for tracking food through the supply chain. The barcode that used to be a scanning convenience is becoming the regulatory infrastructure for food safety. This is not a retailer preference. It is law.
These two deadlines land on a company whose product master would fail basic validation at every contracted retailer today. Fifty of 90 SKUs fail Walmart’s required-field check. Those 50 carry $18.2 million in trailing twelve-month revenue, 71% of the catalog. Costco is nearly as exposed. UNFI and Whole Foods less so, but UNFI’s 54% pass rate still puts $14 million at risk.
| Retailer | SKUs failing | Revenue at risk | Pass rate |
|---|---|---|---|
| Walmart | 50 of 90 | $18.2M | 44% |
| Costco | 48 of 90 | $18.0M | 47% |
| UNFI | 41 of 90 | $14.0M | 54% |
| Whole Foods | 27 of 90 | $9.8M | 70% |
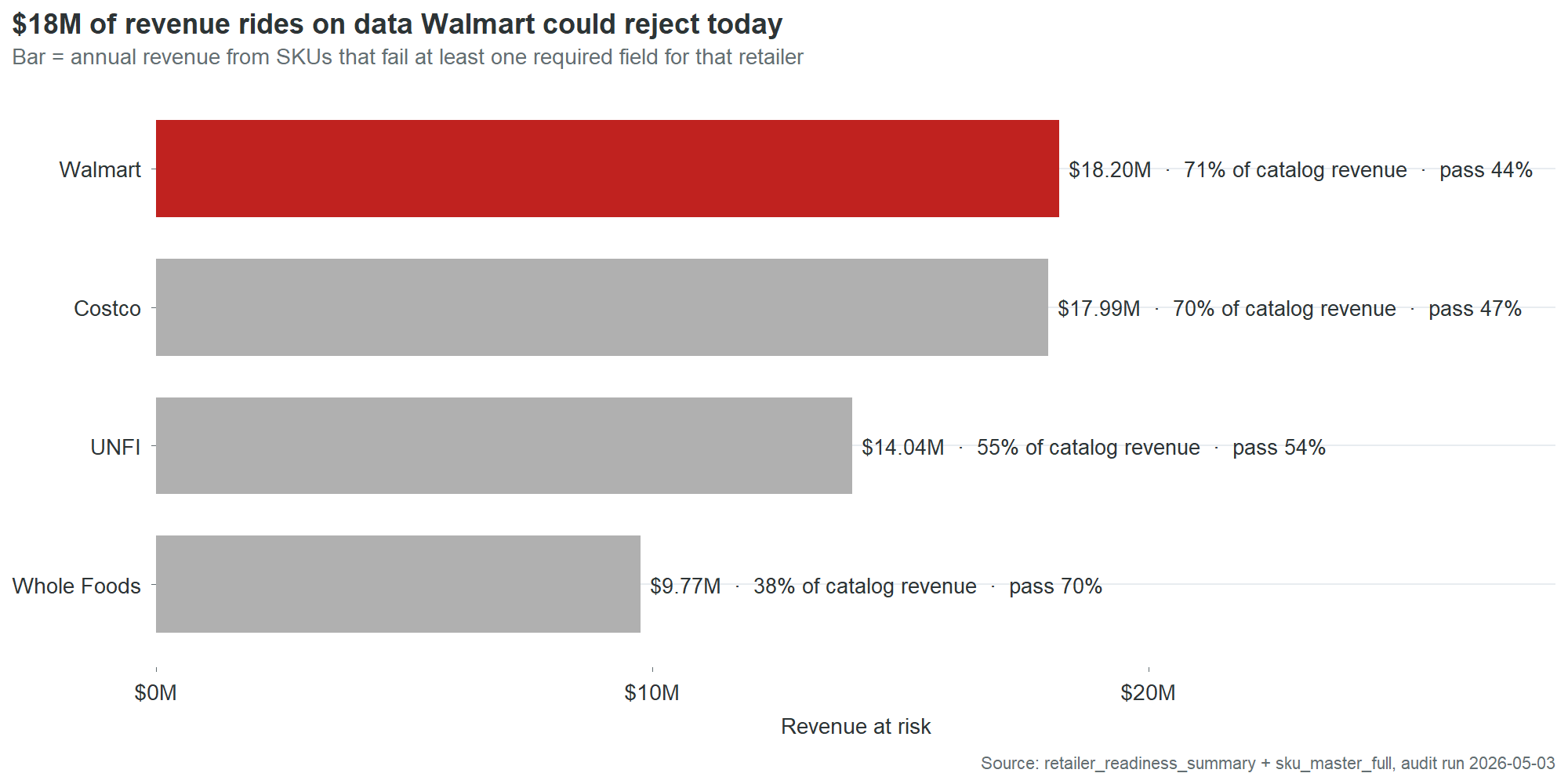
These are not projections of what might happen if data quality degrades. They are measurements of the current product master against the current retailer requirements. The data fails now. The only reason the revenue still flows is that nobody has run the audit yet.
The convergence of retailer readiness gaps, GS1 Sunrise, and FSMA 204 is the wall. Each individually would justify fixing the product master. Together, they create a deadline. A company that reaches 2028 with invalid GTINs, missing case dimensions, and 90% OneWorldSync incompleteness will not have a data quality problem. It will have a market access problem.
The $59,000 in annual chargebacks is what dirty data costs when nobody checks. The $18.2 million in at-risk revenue is what it costs when someone does. The GS1 and FSMA transitions are the moment when everyone checks at once.
The $59,000 you already pay
Cinderhaven’s four contracted retailers deducted $88,000 in chargebacks from settlement payments over the past 18 months. Annualized, that’s $59,000 a year in revenue that left the building before it reached the bank account. Most of it was unnecessary.
Not all chargebacks are created equal. Walmart charges you when your barcode fails a check digit validation. Costco charges you when the case dimensions in the product master don’t match what arrives at the warehouse. UNFI charges you when a required data field is blank. Late deliveries and short shipments also generate charges, but those are logistics problems. This report is about the other kind: the charges that come from wrong, missing, or incomplete product data. Those account for 96% of the chargeback bill.
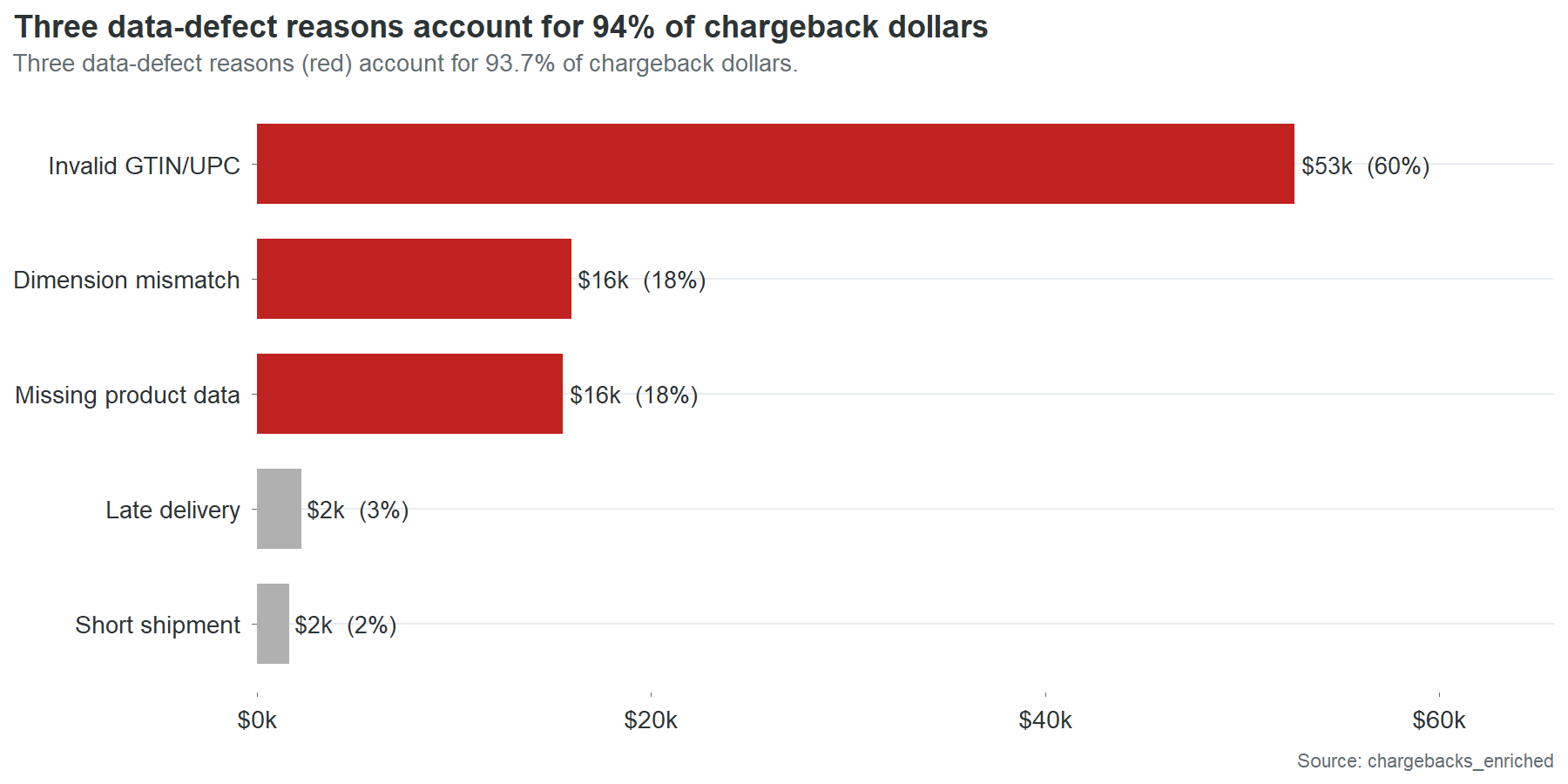
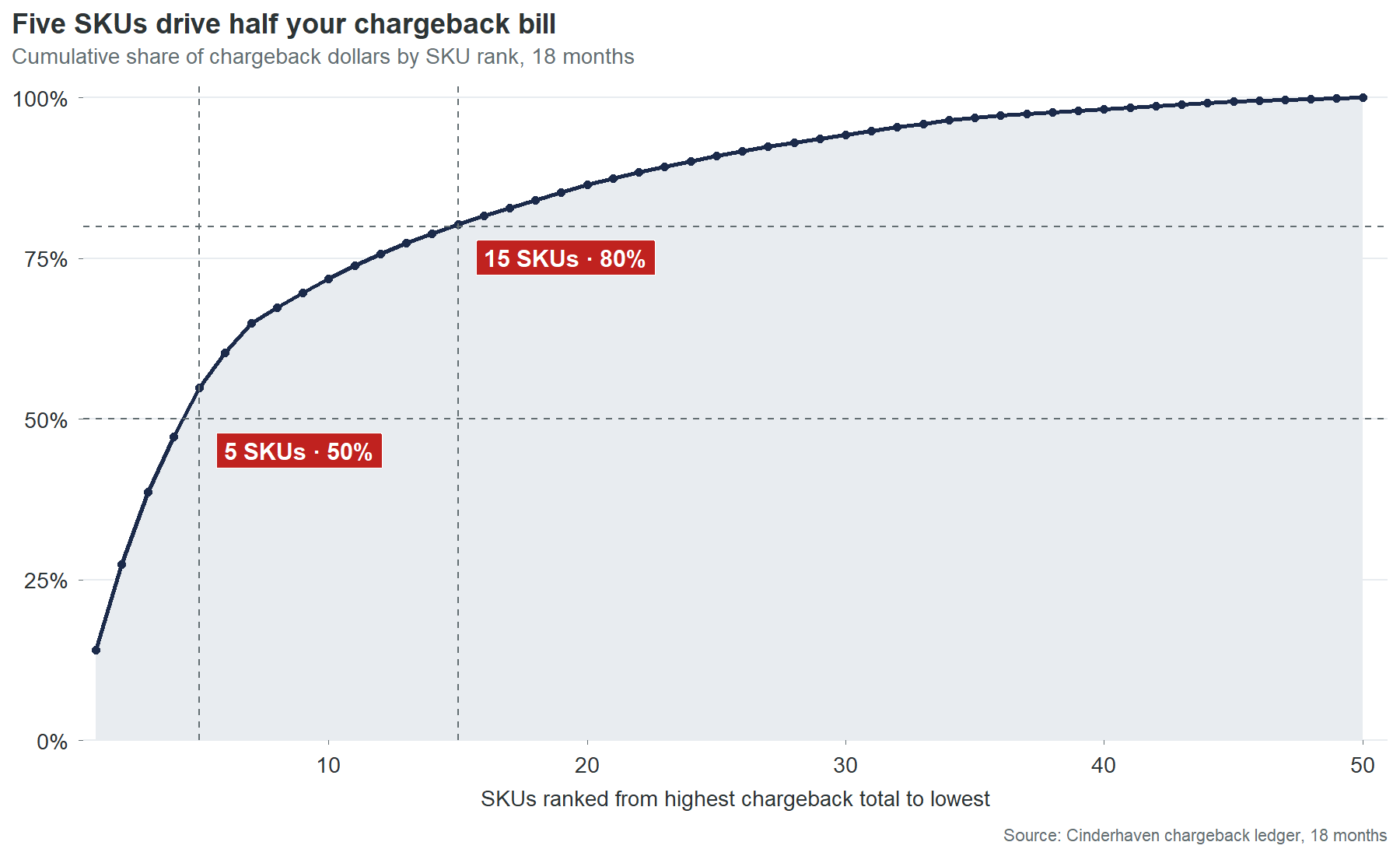
Five SKUs generate half of that bill. Fifteen generate 80%. Forty of your 90 SKUs have never been charged back at all. This is not a catalog-wide crisis. It is a concentrated problem with specific names and specific causes. Here are the names:
| SKU | Product | 18-mo chargebacks | What’s still broken |
|---|---|---|---|
| CHP-0002 | Spicy Arrabbiata | $12,427 | GTIN check digit, brand owner blank |
| CHP-0044 | Charred Scallion Relish | $11,740 | GTIN check digit, case weight implausible |
| CHP-0043 | Cranberry Mostarda | $9,882 | GTIN check digit, case dims blank |
| CHP-0069 | Infused Oil, Lemon Herb | $8,356 | GTIN check digit, case dims blank |
| CHP-0086 | Toasted Sesame Oil | $5,527 | GTIN check digit, case weight implausible |
Every one of these has an invalid GTIN-14 check digit. Every one has at least one other defect layered on top. And every one of these defects is present in the product master right now. Not last year. Not at the time of the last audit. Right now. The charges arrived last month because the same wrong digit that generated the charge the month before is still wrong.
What a wrong barcode costs when nobody is counting
CHP-0002, Spicy Arrabbiata, is the centerpiece of this finding and gets its own section below. But the pattern it represents is worth understanding first through a simpler example.
CHP-0044, Charred Scallion Relish, has one data defect that generates chargebacks: an invalid GTIN-14 check digit. One field. One wrong number. It generated $4,568 in the last six months, about $760 a month, arriving as line items on four different retailer settlement statements. Nobody at Cinderhaven has connected these four monthly line items to each other, because nobody has a process for tracing chargebacks back to specific fields in the product master. The charges look like four separate problems. They are one problem, four times.
Fixing CHP-0044’s check digit takes ten minutes. Open the product master. Recalculate the check digit. Type the correct number. Save. Ten minutes against $9,136 a year. That ratio does not require a business case. It requires someone to know the connection exists.
The waiting room
There is an invisible queue between the moment a retailer authorizes a product and the moment that product generates its first sale. At Cinderhaven, the length of that queue is determined almost entirely by the quality of the product data.
CHP-0022, San Marzano Marinara, was authorized at its first retailer on June 3, 2024. It carries four data defects: an invalid GTIN-14, an invalid UPC-12, a blank brand owner, and missing case dimensions. The retailer’s item setup system received the authorization, attempted to validate the product record, and stalled. The GTIN didn’t pass. The case dimensions were blank, so the warehouse management system couldn’t assign a slot. The record sat in a validation queue while the shelf space it had been allocated sat empty. The first scan didn’t register until July 13. Forty days after the buyer had already approved the product.
A SKU with clean data clears that same queue in 10 days. The difference is not processing speed. It is not retailer bureaucracy. It is the number of automated validation checks that return errors instead of passing, each one adding a manual review step, a correction request back to the vendor, and a resubmission cycle before the product can flow to the distribution center.
Forty days is not the worst case. It is typical for the worst quarter of the catalog:
| Data quality tier | Mean days to shelf |
|---|---|
| Worst 25% | 32 days |
| Below average | 29 days |
| Above average | 13 days |
| Best 25% | 10 days |
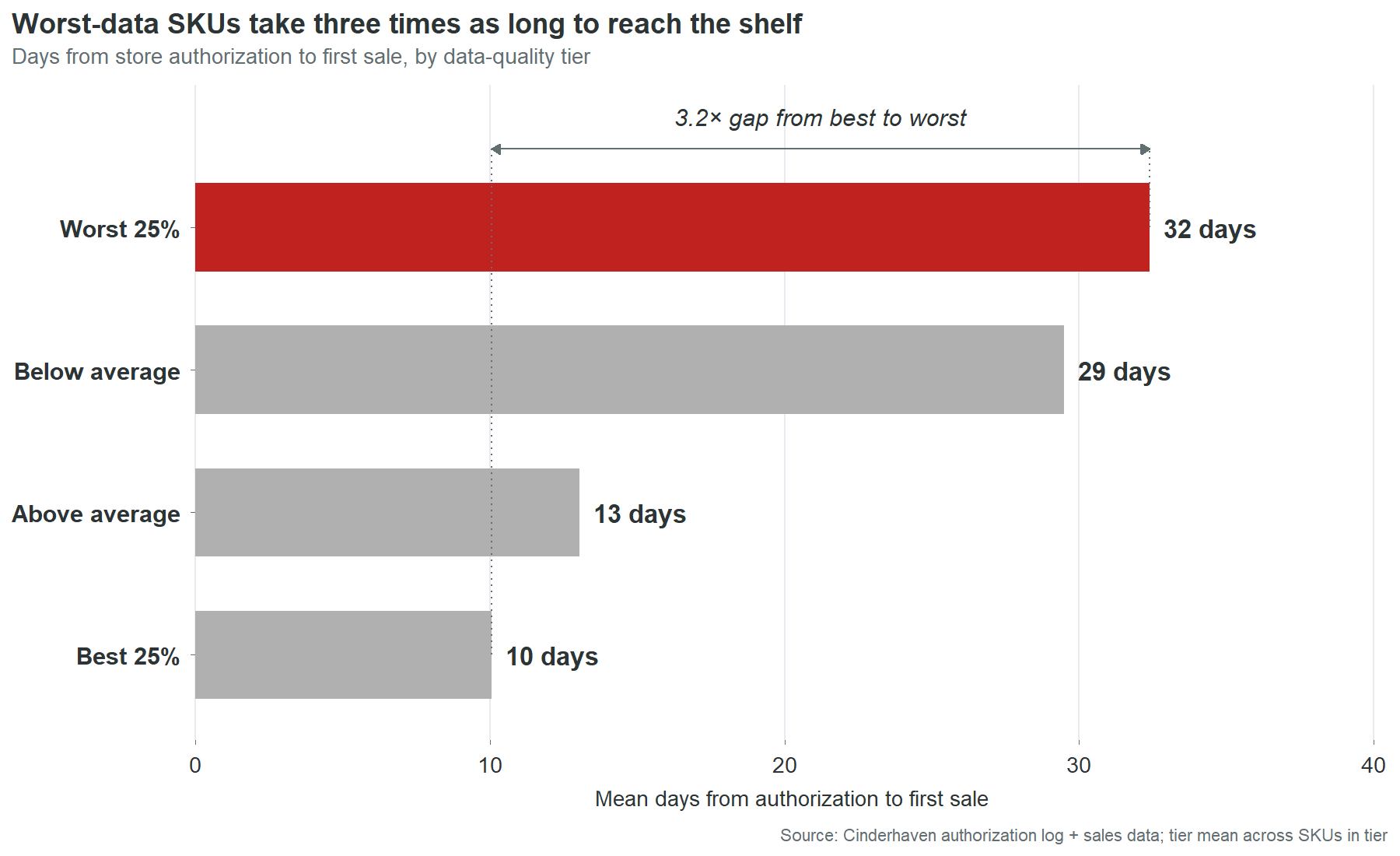
The 22-day spread between worst and best represents revenue that was approved, authorized, and shelf-allocated, waiting in a system queue for someone to fix a data field. Not waiting for a buyer decision. Not waiting for a logistics window. Waiting for a digit to be corrected in a record that nobody at Cinderhaven knew was wrong, because nobody at Cinderhaven tracks authorization-to-first-scan as a metric.
This is the cost that doesn’t have a line item. Chargebacks arrive as deductions on a settlement statement. Stalled revenue doesn’t arrive at all. It is the absence of revenue during a window when revenue should have been flowing. Nobody notices because there is no alert, no report, no dashboard that says “this product was authorized 30 days ago and hasn’t scanned yet.” The authorization is celebrated. The gap is never measured. The revenue loss is real but invisible.
At CHP-0022’s daily revenue rate, 30 extra days costs roughly $1,400. That’s a small SKU. Apply the same math across all 46 SKUs outside the best quality tier, scaled by their revenue and their actual time-to-shelf gaps, and the catalog-wide cost is $234,000 a year. This estimate assumes revenue accrues linearly with shelf time and that delayed launch revenue is not recovered in later periods. Both assumptions are conservative. In specialty food, launch windows are competitive and seasonal. A product that misses its first three weeks during a promotional period doesn’t get those weeks back. A competitor’s product fills the gap. The revenue doesn’t shift to next month. It vanishes.
The slots you don’t get back
The progression from chargebacks to stalled revenue to shelf loss follows a severity curve. Chargebacks take your money. Stalled launches take your time. Shelf loss takes your position.
CHP-0069, Infused Oil, Lemon Herb, was authorized across 248 Walmart stores. It carries three data defects: an invalid GTIN-14, an invalid UPC-12, and missing case dimensions. Over the first ten months of its Walmart authorization, these defects generated a steady trickle of chargebacks. Two events, $822. Small enough to disappear into the settlement statement. Not small enough for Walmart’s compliance system to ignore.
In March 2025, Walmart deauthorized CHP-0069 at two stores. Store WMT-0408 on March 3. Store WMT-0217 three weeks later. The product was pulled from two locations, and two shelf slots were filled by whatever the category manager had next in the queue. Those slots are gone. Winning them back requires a new category review, which happens once a year at Walmart, and a pitch that explains why the product that was pulled for data defects won’t be pulled again.
Two stores out of 248 sounds minor. It isn’t. It’s the signal that Walmart’s system has flagged this SKU. The defects that triggered the deauthorizations at WMT-0408 and WMT-0217 are identical to the defects still present at the other 246 stores. The GTIN is still invalid. The case dimensions are still blank. Since the two deauthorizations, Walmart has issued 18 more chargeback events against CHP-0069 at the remaining stores, totaling $6,699. The charges are running at $400 to $500 a month with no sign of stopping. The two deauthorized stores were not the punishment. They were the warning shot. The unfixed data is the loaded gun still pointed at the other 246.
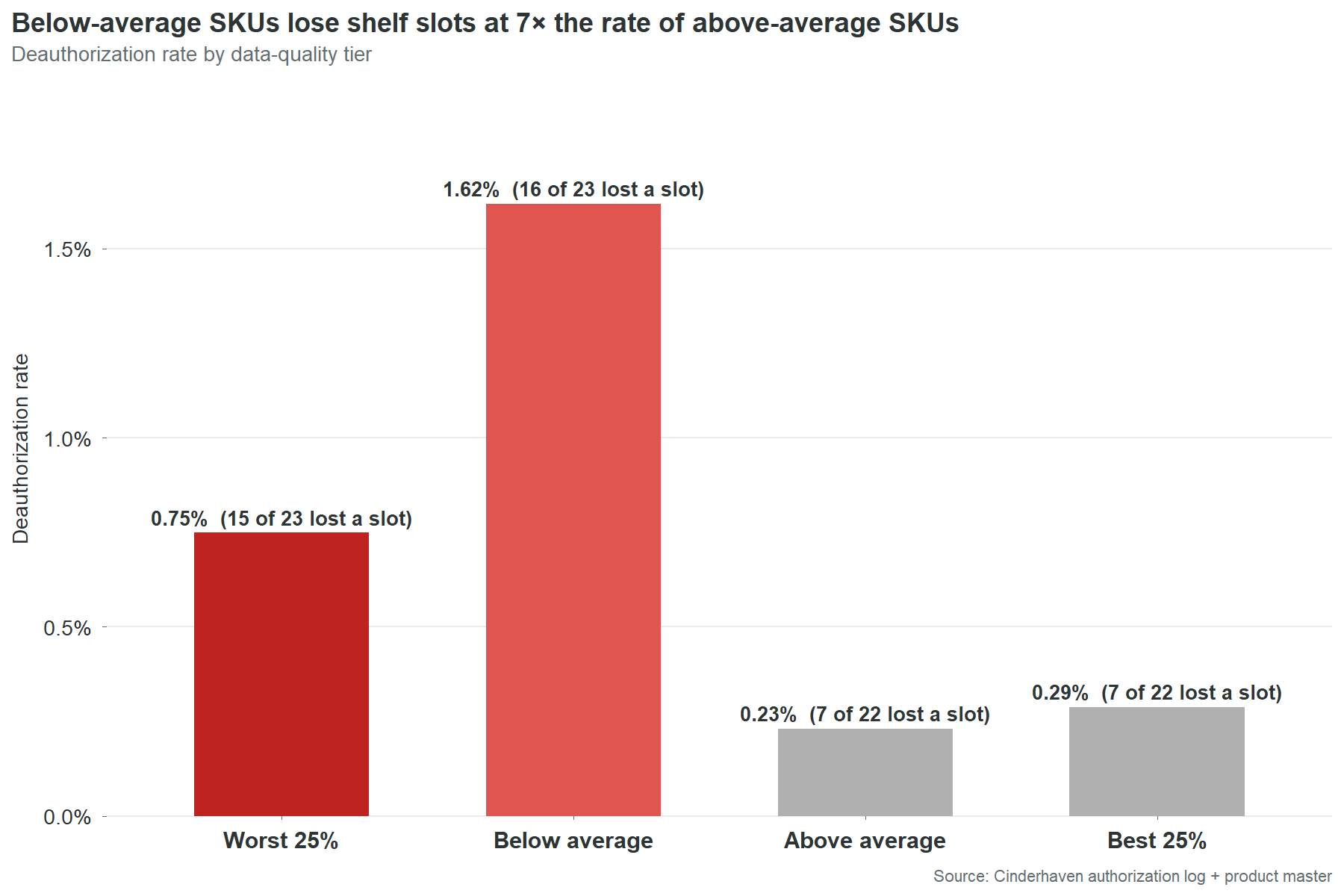
The pattern is not unique to CHP-0069. Bottom-half data quality SKUs get deauthorized at 4.5 times the rate of top-half SKUs. Thirty-one of 45 bottom-half SKUs have lost at least one slot. Fourteen of 45 top-half SKUs have. The data cannot prove that every deauthorization is a direct consequence of data quality. Retailers remove products for many reasons: poor velocity, planogram resets, category rationalization. But the correlation between data quality and deauthorization rate is the strongest signal in this dataset after the chargeback-to-defect linkage. The SKUs with the worst data lose shelf space at 4.5 times the rate. That is not a coincidence that disappears with a larger sample. That is a pattern that gets worse.
The cost of a deauthorization is not the lost revenue at that store. It is the competitive displacement. A specialty food brand does not compete for abstract “shelf space.” It competes for specific slots in specific planograms that are reviewed on 12-to-24-month cycles. Losing a slot to a competitor means that competitor’s product will generate 12 to 24 months of velocity data at that location, data the category manager will use to justify keeping it during the next review. The brand that lost the slot has to overcome a year of incumbent velocity data with nothing but a pitch deck and a promise. The cost is not $400 a month in chargebacks. The cost is two years of competitive disadvantage at every location where the deauthorization spreads.
The $691-a-month problem nobody sees
The nine invalid GTIN check digits in Cinderhaven’s product master have been wrong since the day each SKU was entered. The earliest was entered in June 2024. That was 23 months ago. In those 23 months, nobody corrected a single one of the nine digits. Not because anyone decided the chargebacks were acceptable. Because nobody knew the chargebacks and the digits were connected.
The chain of visibility works like this. A retailer’s automated system validates the GTIN on an inbound shipment or a data feed submission. The check digit fails. The system generates a compliance penalty. The penalty appears as a line item on the next settlement statement, categorized under a heading like “vendor compliance deductions” or “data quality fines.” The settlement statement is 40 pages long. It contains hundreds of line items. The compliance penalties are scattered across pages 12 through 30, interleaved with promotional deductions, logistics credits, and payment adjustments. An individual penalty is $200 to $400. It does not trigger an investigation. It does not cross an approval threshold. It does not generate an alert.
On the other side, the product master sits in whatever system Cinderhaven uses to manage product data. It might be an ERP. It might be a shared Excel file. It might be a combination of both. The GTIN-14 field contains a 14-digit number that was typed once, by whoever set up the SKU, and has not been opened since. Nobody reviews GTIN fields. Nobody runs check digit validations. Nobody has a process for connecting a chargeback on page 14 of a Walmart settlement statement to a digit in row 44 of the product master.
The ops team is not negligent. They are fully occupied. Four retailer portals. Broker coordination. Velocity reports rebuilt by hand every Monday. Trade spend reconciliation. New SKU launches. Promotional planning. Data cleanup is on the list. It is always on the list. It sits between “update the trade spend template” and “fix the label printer” and it never reaches the top because the chargebacks arrive in amounts too small to demand attention and too steady to ever stop on their own.
CHP-0002 has generated 50 chargeback events in 18 months. An average of $691 a month. Fifty times, the system flagged the same wrong digit, generated the same penalty, deducted it from the same settlement, and nobody traced it back. Not because tracing it was hard. Because nobody knew to look.
This is the structural problem beneath all four cost categories. The chargebacks persist because the defects persist. The defects persist because nobody has time to find them. Nobody has time to find them because the cost of each individual defect is too small to surface through normal business processes. The total is $361,000 a year. The individual units are invisible. The system that would make them visible does not exist yet. Part 3 of this report describes what that system looks like.
The revenue you’re not capturing
The cost story is about money leaving. This is about money that never arrives.
Forty of Cinderhaven’s 90 SKUs pass Walmart’s required-field check today. These are the products that could be submitted for a new Walmart line review, a planogram expansion, or a regional test without any data work. They are ready. The data is clean. The barcodes validate. The case dimensions are populated. The OneWorldSync records exist.
Those 40 SKUs generate $7.3 million in trailing twelve-month revenue across all channels. They are, on average, the smaller products in the catalog.
The 50 that fail generate $18.2 million.
This is the inversion that makes the revenue story uncomfortable. The products with the cleanest data are not the biggest sellers. The biggest sellers have the dirtiest data. The catalog’s growth potential is concentrated in exactly the SKUs that cannot pass a retailer readiness check. Every expansion conversation runs into the same wall: the products you most want to expand are the ones whose data isn’t ready to expand with them.
Twenty of those 50 failing SKUs are already shipping to Walmart. They were authorized before the requirements tightened, or before anyone checked. They are generating revenue on borrowed time.
| SKU | Product | TTM revenue |
|---|---|---|
| CHP-0002 | Spicy Arrabbiata | $2.71M |
| CHP-0071 | Balsamic Vinegar, Aged 12yr | $2.01M |
| CHP-0043 | Cranberry Mostarda | $1.51M |
| CHP-0042 | Everyday Sriracha | $1.33M |
| CHP-0009 | Classic Bolognese | $1.08M |
| CHP-0027 | Artichoke & Lemon Cream | $1.00M |
| CHP-0044 | Charred Scallion Relish | $974k |
| CHP-0038 | Cherry Pepper Mostarda | $878k |
| CHP-0063 | Everything Bagel Seasoning | $853k |
| CHP-0031 | Stone Ground Mustard | $736k |
$15.1 million in Walmart-channel revenue riding on data that Walmart’s own system would reject. Four of these appear in both this table and the top chargeback offenders list. The data defects are not hypothetical risk. They are already generating deductions on products that are already selling. The risk and the cost are happening simultaneously.
The other 30 failing SKUs are not authorized at Walmart today. They are the expansion queue. If Cinderhaven wants to pitch a Walmart line extension, and at $25 million in revenue scaling toward $55 million, that pitch is coming, those 30 SKUs need their data fixed before the conversation starts. Not during the conversation. Before. A retailer’s category team does not fix vendor data. They evaluate what’s submitted. If the submission fails their automated checks, the conversation ends before a human being ever sees the product.
The counterintuitive finding makes this worse. Failing SKUs have slightly higher average velocity than passing SKUs: 11.3 units per store per week versus 10.6. The products with the worst data are selling faster than the products with the best data. The readiness gate is screening on data completeness, not commercial viability. The products being blocked from expansion are the ones the market wants most.
The gap between “blocked” and “ready” for most of these SKUs is two to three fields. Brand owner. GTIN check digit. Case dimensions. The work is measured in hours, not weeks. The 50 failing SKUs are not 50 product development problems. They are 50 data entry tasks. The difference between $7.3 million in expansion-ready revenue and $25.5 million in expansion-ready revenue is approximately 27 hours of clerical work. That is the most underspent 27 hours in the company.
The SKU you can’t afford to ignore
CHP-0002, Spicy Arrabbiata, is the best-selling product in the Cinderhaven catalog. $2.7 million in trailing twelve-month revenue. 774 stores across every channel. Velocity of 10 units per store per week, steady across 53 consecutive weeks. It represents 10.6% of company revenue and over a million dollars in annual gross margin. If Cinderhaven has a flagship, this is it.
It is also the single largest source of chargeback cost in the catalog. Fifty chargeback events over 18 months. $12,427 in penalties deducted from settlement payments across all four contracted retailers. Not clustered in one bad quarter. Not triggered by one bad shipment. Fifty events spread across 18 consecutive months, arriving at a rate of roughly three per month, because the same two data defects trigger the same automated validation failures at the same four retailers, month after month, without interruption.
The defects are not complex. The GTIN-14 check digit is wrong. The brand owner field contains the two-character string “NA” instead of a company name. The OneWorldSync record was never created. The GTIN defect alone accounts for 96% of CHP-0002’s chargeback dollars. Forty-eight of the 50 events trace to a single wrong digit in a single field.
In five of the 18 months, all four contracted retailers flagged CHP-0002 in the same month. Walmart, Costco, UNFI, and Whole Foods, independently running their own validation checks, independently finding the same wrong digit, independently issuing penalties. This is the diagnostic signature of a master data defect: multiple retailers flagging the same SKU for the same reason in the same time window. It is not a dispute about terms. It is not a disagreement about a shipment. It is an automated system doing exactly what it was designed to do, finding a wrong number and charging for it, and it will continue doing it every month until someone changes the number.
CHP-0002 would fail every retailer’s required-field check today. Not one. All four. The product is authorized at 774 stores and its data would not survive the onboarding process at any of them if it were submitted fresh. It was authorized before the checks existed or before they were enforced at their current stringency. It survives on inertia, not on data quality.
The contrast is instructive. CHP-0020, Truffle Mushroom Cream, sits at #3 in the revenue rankings at $1.95 million. Same product line. Comparable scale. Data quality score of 87.5 versus CHP-0002’s 62.5. Two chargeback events in 18 months, totaling $552. Passes all four retailer readiness checks.
| CHP-0002 | CHP-0020 | |
|---|---|---|
| TTM revenue | $2.71M | $1.95M |
| Data quality score | 62.5 | 87.5 |
| 18-month chargebacks | $12,427 | $552 |
| Chargeback events | 50 | 2 |
| Retailers passing | 0 of 4 | 4 of 4 |
Two products at comparable revenue. One generates 22 times more chargeback cost than the other. The 22x gap is not explained by any commercial difference. It is explained entirely by two data fields.
This pattern extends across the top of the catalog:
| Rank | Product | Revenue | DQ score | Chargebacks | Retailers passing |
|---|---|---|---|---|---|
| 1 | Spicy Arrabbiata | $2.71M | 62.5 | $12,427 | 0 of 4 |
| 2 | Balsamic Vinegar, Aged 12yr | $2.01M | 87.5 | $531 | 1 of 4 |
| 3 | Truffle Mushroom Cream | $1.95M | 87.5 | $552 | 4 of 4 |
| 4 | Cranberry Mostarda | $1.51M | 50.0 | $9,882 | 1 of 4 |
| 5 | Everyday Sriracha | $1.33M | 62.5 | $229 | 0 of 4 |
| 6 | Classic Bolognese | $1.08M | 62.5 | $1,131 | 1 of 4 |
| 7 | Artichoke & Lemon Cream | $1.00M | 62.5 | $855 | 0 of 4 |
| 8 | Charred Scallion Relish | $974k | 62.5 | $11,740 | 2 of 4 |
| 9 | Cherry Pepper Mostarda | $878k | 50.0 | $827 | 0 of 4 |
| 10 | Everything Bagel Seasoning | $853k | 62.5 | $2,018 | 1 of 4 |
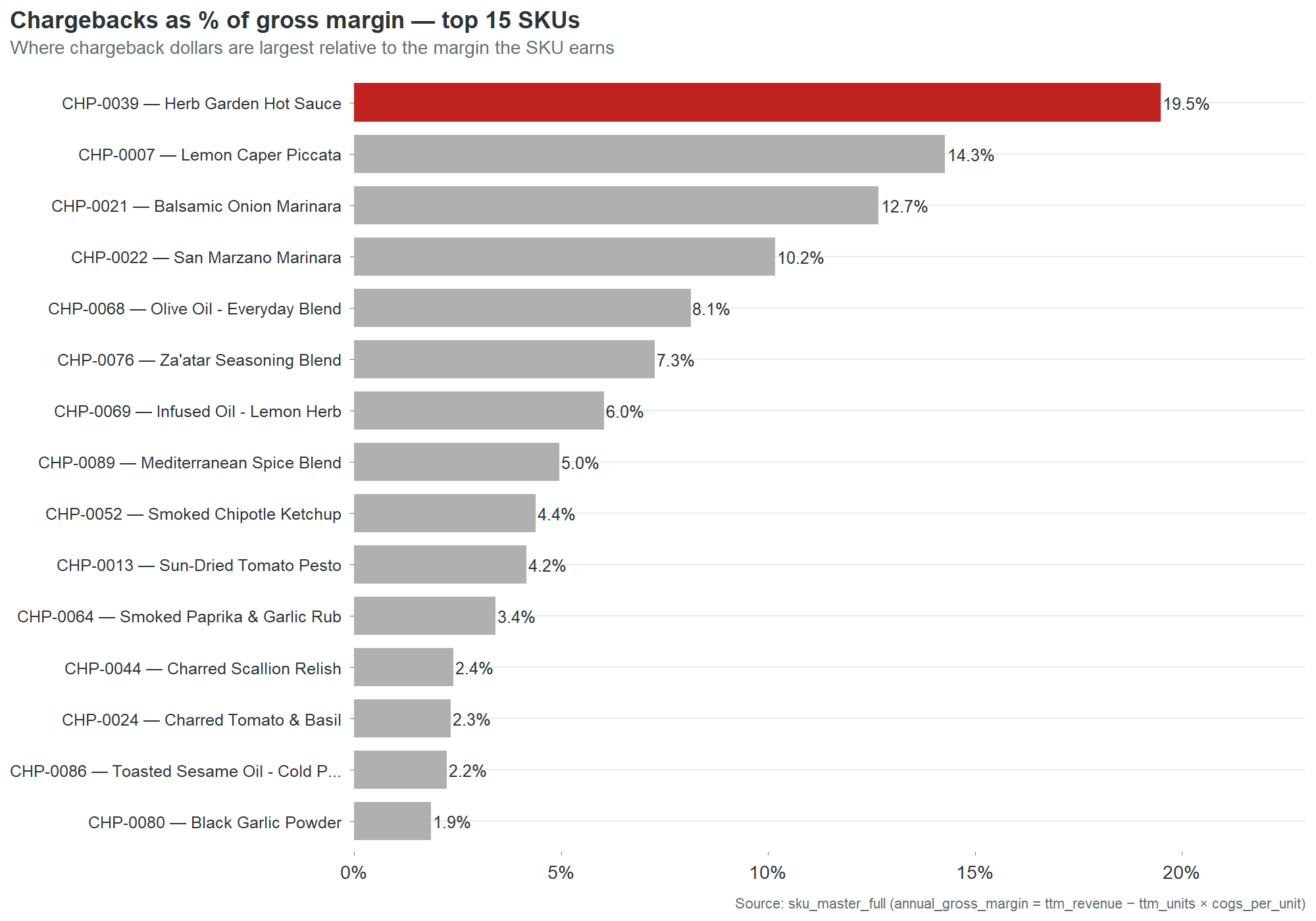
Only one of the top 10 passes all four retailers. Six pass zero or one. The $16.1 million in revenue at the top of the catalog, 63% of the company, rides on data that would fail most retailer onboarding processes.
The assumption that the highest-revenue products must have the best data is not just wrong. It is precisely inverted. The products that generate the most revenue received the same one-time data entry as every other product. They just generate larger penalties when that entry is wrong, attract more retailer scrutiny because of their volume, and create more exposure when a readiness audit runs. The risk concentrates at the top because revenue concentrates at the top. The data quality does not.
Fixing CHP-0002 takes 40 minutes. Correct the GTIN check digit. Replace the “NA” in the brand owner field with “Cinderhaven Provisions.” Submit the OneWorldSync registration. When that’s done, $8,300 a year in chargebacks stops and the #1 SKU passes all four retailer readiness checks. The risk that Walmart runs an Item 360 audit and flags the company’s flagship product goes from certain failure to clean pass.
The risk of leaving it unfixed is not the $8,300. The risk is that a retailer runs the check. Walmart doesn’t send a chargeback for a readiness failure. Walmart sends a deauthorization. And when the #1 SKU, 10.6% of company revenue, a million dollars in annual gross margin, loses its largest retailer, the conversation is not with the data team. It is with the board.
Part 2: Why It Happens
Part 1 showed what data debt costs. This section is about where it comes from. Four causes, each one fixable, none of them surprising once you see them. The frustrating part is how ordinary they are.
The open door: why the product master is a free-for-all
Cinderhaven’s product master was built the way most $25 million companies build a product master: by whoever had 20 minutes. Thirteen SKUs were uploaded by a broker. Nineteen were entered by the production admin. Seventeen by inventory admin. Twelve came through an import script. Ten by the quality manager. Ten by an ops coordinator. Nine have no recorded entry source at all. Seven different paths into the same system, and not one of them requires the data to be validated before it goes live.
There is no intake checklist. No required field set enforced at entry. No validation step between “someone typed this” and “retailers are ordering against it.” A broker can upload a SKU with a wrong check digit, a blank brand owner, and missing case dimensions, and the record goes live the moment it’s saved. The first validation that record will ever receive is a retailer’s automated compliance check, six months later, when it fails and generates a $300 penalty that nobody traces back to the upload.
| Entry source | SKUs | Chargebacks per SKU |
|---|---|---|
| quality_mgr | 10 | $1,444 |
| broker_upload | 13 | $1,435 |
| import_script | 12 | $1,413 |
| inventory_admin | 17 | $1,343 |
| production_admin | 19 | $513 |
| ops_coordinator | 10 | $269 |
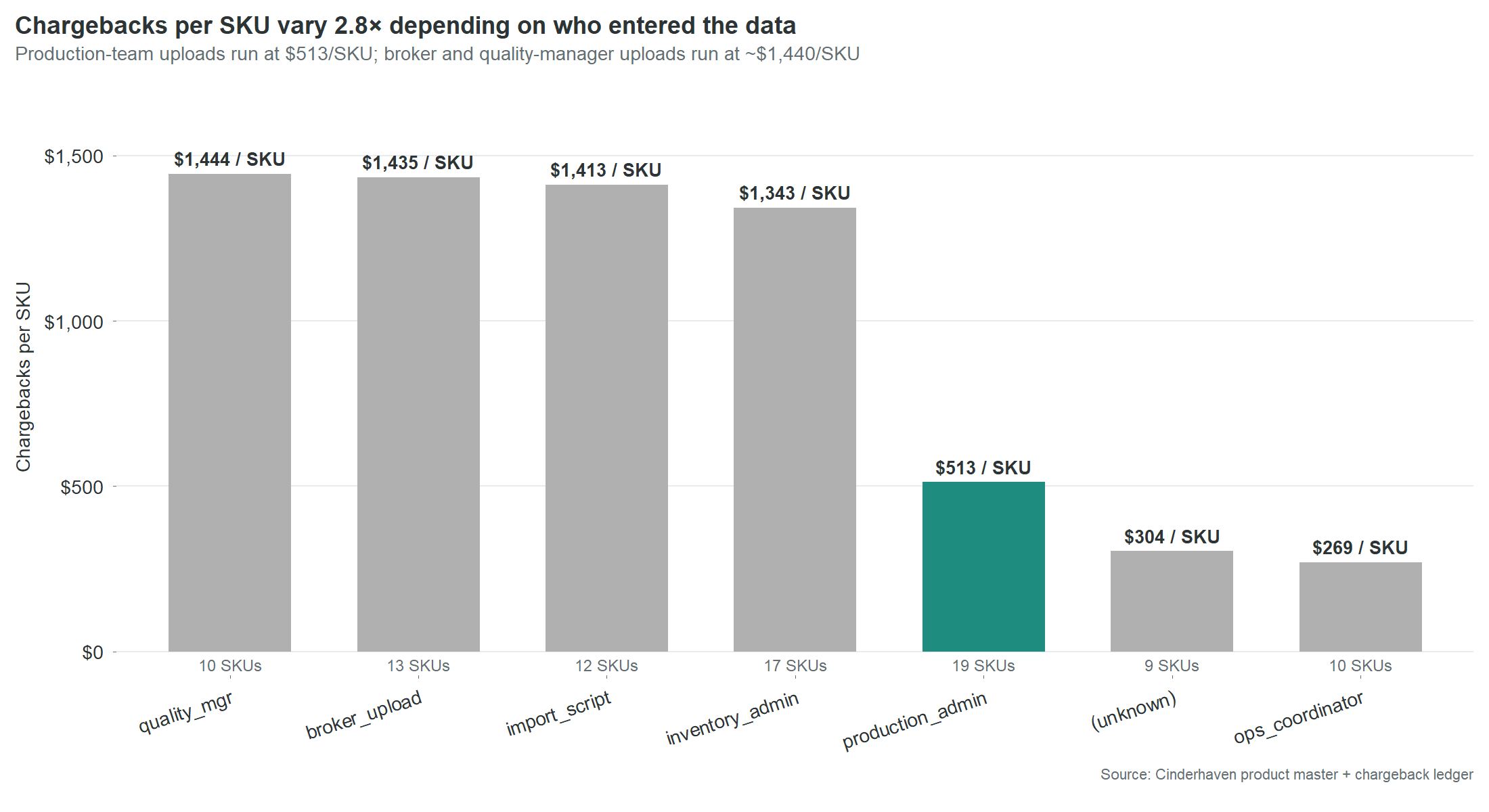
The conventional reading is that broker uploads are the problem. The table says otherwise. Four different entry paths, operated by four different roles with four different levels of product knowledge, all produce essentially the same expensive result. The problem is not who is entering the data. The problem is that nobody is checking it.
The two sources that produce materially better results share one characteristic the others do not. Production admin and ops coordinator enter data as a primary responsibility, not as an interruption between other tasks. The distinction is not skill or diligence. It is attention. The people who produce clean data are the people whose job makes data entry the main task, not the side task.
This is not fixable by training. Training addresses skill gaps. This is an attention gap. The fix is structural: a gate between data entry and the live product master. The broker intake checklist in the appendix defines eight fields that must be populated and validated before a SKU record can go live. It takes five minutes to fill out. But the checklist is not just for brokers. Every path into the product master needs the same front door because every path without one produces the same result.
The nine SKUs with no recorded entry source at all are a separate finding. They represent a gap not just in data quality but in data governance. Nobody knows who entered these records. Nobody knows when. Nobody knows what process, if any, was followed. These nine SKUs are the clearest evidence that the product master is an unmanaged asset. It is the most important data system in the company, every retailer relationship, every chargeback, every velocity report, every shelf placement depends on it, and it has no owner, no process, and no audit trail.
The products that matter most get the least attention
The centerpiece section showed CHP-0002 in detail: the #1 revenue SKU with the #1 chargeback total. That’s not an anomaly. It’s the pattern.
The top 15 SKUs by revenue have a mean data quality score of 66.7. The catalog averages 70.0. Six of the top 10 revenue SKUs pass zero or one of four retailer readiness checks. Only one, CHP-0020 Truffle Mushroom Cream, passes all four.
The instinct is to assume this will sort itself out. The big sellers get attention. Attention leads to cleanup. The assumption is wrong because it confuses commercial attention with data attention. Everyone at Cinderhaven knows that Spicy Arrabbiata sells $2.7 million a year. Nobody at Cinderhaven knows that Spicy Arrabbiata’s GTIN-14 check digit is wrong. Those are two different kinds of knowing, and only the first one happens naturally.
Data entry is clerical work. It happens at launch, when somebody has 20 minutes between other tasks, and it never happens again. Nobody revisits the product master after a SKU is selling. The record freezes at whatever state it was in on the day someone typed it. A $2.7 million SKU and a $15,000 SKU both get one pass through data entry. The $2.7 million SKU just generates larger chargebacks when the entry is wrong.
The fix does not require better data entry. It requires a list. Put the revenue number next to every SKU on the ops team’s screen. Sort by revenue. Start at the top. The people doing the work have never been shown which products their work protects. Give them that information and the triage takes care of itself.
You are allocating resources to the wrong retailer
Walmart generates $13.1 million in gross revenue. That’s 51% of the catalog. It is the largest channel by every gross metric. It is not the most profitable.
| Retailer | Gross | Trade spend | Chargebacks | Net margin |
|---|---|---|---|---|
| Whole Foods | $2.78M | 12.5% | 0.36% | 87.0% |
| UNFI | $4.27M | 15.1% | 0.61% | 84.3% |
| Costco | $2.25M | 16.4% | 0.40% | 82.4% |
| Walmart | $13.10M | 21.3% | 0.33% | 78.4% |
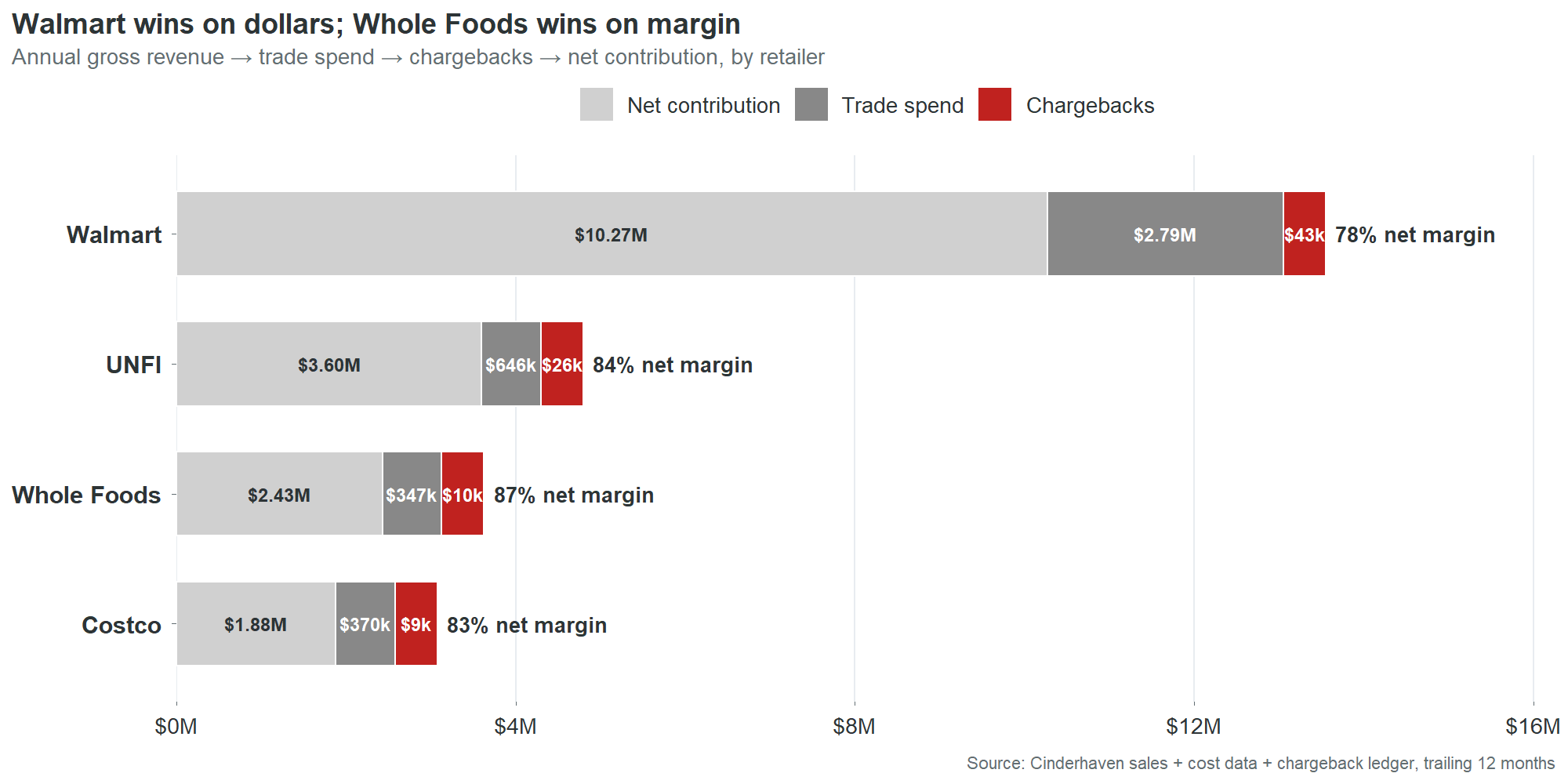
Whole Foods contributes 87 cents of margin on every dollar of revenue. Walmart contributes 78 cents. The nine-cent gap is almost entirely trade spend.
This table reorders the CEO’s priorities. Not away from Walmart. Walmart generates $10.27 million in net contribution. You don’t walk away from that. But you stop assuming that Walmart volume equals Walmart profitability when deciding where to invest ops resources, which retailer gets the first call when there’s a data issue, and which expansion opportunity gets prioritized.
The chargeback column reveals something else. The rates are small at every retailer, between 0.33% and 0.61% of revenue. But chargebacks are the only margin lever entirely within Cinderhaven’s control. Trade spend is negotiated once a year. Chargebacks are generated by data defects that Cinderhaven can fix any Tuesday afternoon. Every dollar recovered drops straight to net contribution with no negotiation, no pitch deck, no relationship risk.
UNFI is the overlooked story. It generates $26,000 in chargebacks, 30% of the total, despite being the #2 retailer by revenue. Its chargeback rate (0.61% of revenue) is the highest of the four. UNFI’s compliance requirements are less visible than Walmart’s. The data says they enforce them just as consistently. A cleanup that focuses on Walmart because Walmart is the biggest name leaves $26,000 of UNFI chargebacks untouched and a 0.61% bleed rate unaddressed at the retailer with the second-best margin density.
One product line already has better outcomes. The reason isn’t what you’d guess.
Data debt is not evenly distributed.
| Product line | Revenue | Issues per $1M | Chargebacks per $1M |
|---|---|---|---|
| Pantry Staples | $6.49M | 11.3 | $2,506 |
| Specialty Condiments | $8.71M | 8.5 | $4,662 |
| Artisan Sauces | $10.35M | 6.7 | $3,013 |
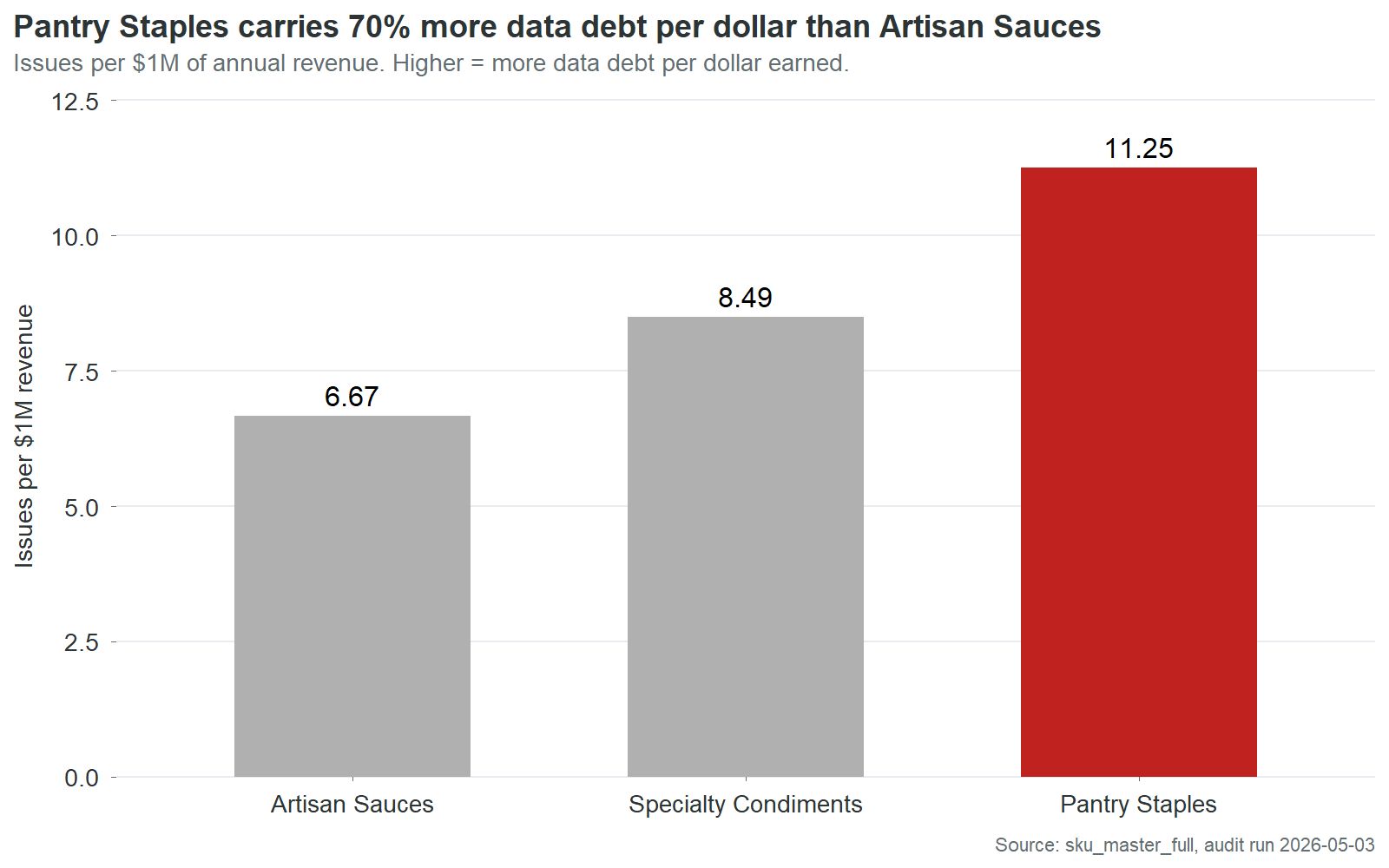
Pantry Staples carries 70% more data issues per dollar of revenue than Artisan Sauces. The two worst lines are close enough to treat as one cleanup tier. But Artisan Sauces is meaningfully better across every metric.
The obvious hypothesis is that Artisan Sauces routes through a better data entry process. It doesn’t. The cross-tab between product line and entry source shows Artisan Sauces actually over-indexes on quality_mgr, one of the most expensive entry sources at $1,444 in chargebacks per SKU. Specialty Condiments, which has worse outcomes, is the line that disproportionately flows through production_admin, the cleanest source.
The process theory doesn’t hold. Something else is producing Artisan Sauces’ better outcomes despite using expensive entry paths.
Two explanations survive the data. First, Artisan Sauces is the highest-revenue product line. Its SKUs are more likely to have attracted retailer scrutiny, category review attention, and incidental cleanup during quarterly business reviews. Revenue creates visibility. Visibility creates corrections. Second, Artisan Sauces has been in the catalog longest as a line. More time means more cycles through retailer item setup, more rounds of chargeback-driven fixes, more opportunities for someone to notice a defect and correct it. The data is not cleaner by design. It is cleaner by attrition.
Both explanations point to the same conclusion: data quality at Cinderhaven is not managed. It is accidental. The SKUs that get cleaner are the ones that somebody happens to look at for some other reason. A revenue-weighted triage process would make this deliberate instead of incidental. The Artisan Sauces outcome would become the standard, not the exception. And it would happen in weeks, not years.
Part 3: What to Do About It
Ninety minutes against $35,000
Nine SKUs have invalid GTIN-14 check digits. A check digit is a mathematical typo: the last digit of a barcode, calculated from the preceding digits using a standard algorithm. It exists so scanning systems can detect keying errors. When the digit is wrong, the barcode fails validation, the retailer issues a penalty, and the penalty arrives on the settlement statement looking like a cost of doing business. It is not. It is a cost of a wrong digit.
Each of the nine takes about ten minutes to fix. The algorithm is deterministic. The input is already in the record. The fix is arithmetic, not judgment.
Those nine SKUs generated $52,661 in chargebacks over 18 months. Annualized, that’s $35,000 a year. 205 chargeback events across all four contracted retailers. Every event was triggered by the same mechanism: a system ran a calculation, compared the result to the digit on file, found they didn’t match, and issued a charge. The digit on file has been wrong since the day each SKU was entered. It is still wrong now.
Ninety minutes of data entry. $35,000 a year. $389 per minute. The return on this fix is not a number that belongs in a business case. It belongs in a case study about organizational blind spots. The fix has been available for as long as the defect has existed. The cost has been accumulating every month. The connection between the two has never been visible because no system, no report, and no process at Cinderhaven links chargebacks to specific fields in the product master. This report is that link. The connection is now visible. What happens next is a decision, not a discovery.
The second fix is case dimensions. Twenty-one SKUs have blank case weight, length, width, or height fields. When a retailer’s warehouse receives a case and attempts to reconcile it against the product master, the master says nothing. Any measurement is a mismatch against a blank field. Someone pulls a case from inventory, measures it with a tape measure and a scale, and enters five numbers. About 30 minutes per SKU. Twenty-one SKUs, roughly 10 to 11 hours total. That eliminates 18% of chargeback dollars: $15,938 over 18 months, approximately $10,600 a year.
The third fix is missing product data. Eighteen SKUs have blank or placeholder values in required fields: brand owner, country of origin, or other retailer-mandated attributes. Seventeen of the eighteen brand owner cases contain the literal string “NA,” two characters typed by whoever set up the SKU instead of the company name. Replacing “NA” with “Cinderhaven Provisions” takes less time than reading this sentence. The other fields require slightly more work: a phone call to a supplier for imported ingredients, a lookup in an internal system for regulatory codes. Call it 15 hours total across 18 SKUs.
| Fix action | SKUs | Time | Annual savings | Per minute |
|---|---|---|---|---|
| Fix GTIN check digits | 9 | 90 min | $35,000 | $389/min |
| Reconcile case dimensions | 21 | 10.5 hr | $10,600 | $17/min |
| Complete missing fields | 18 | 15 hr | $10,400 | $12/min |
| Total | ~27 hr | $56,000 |
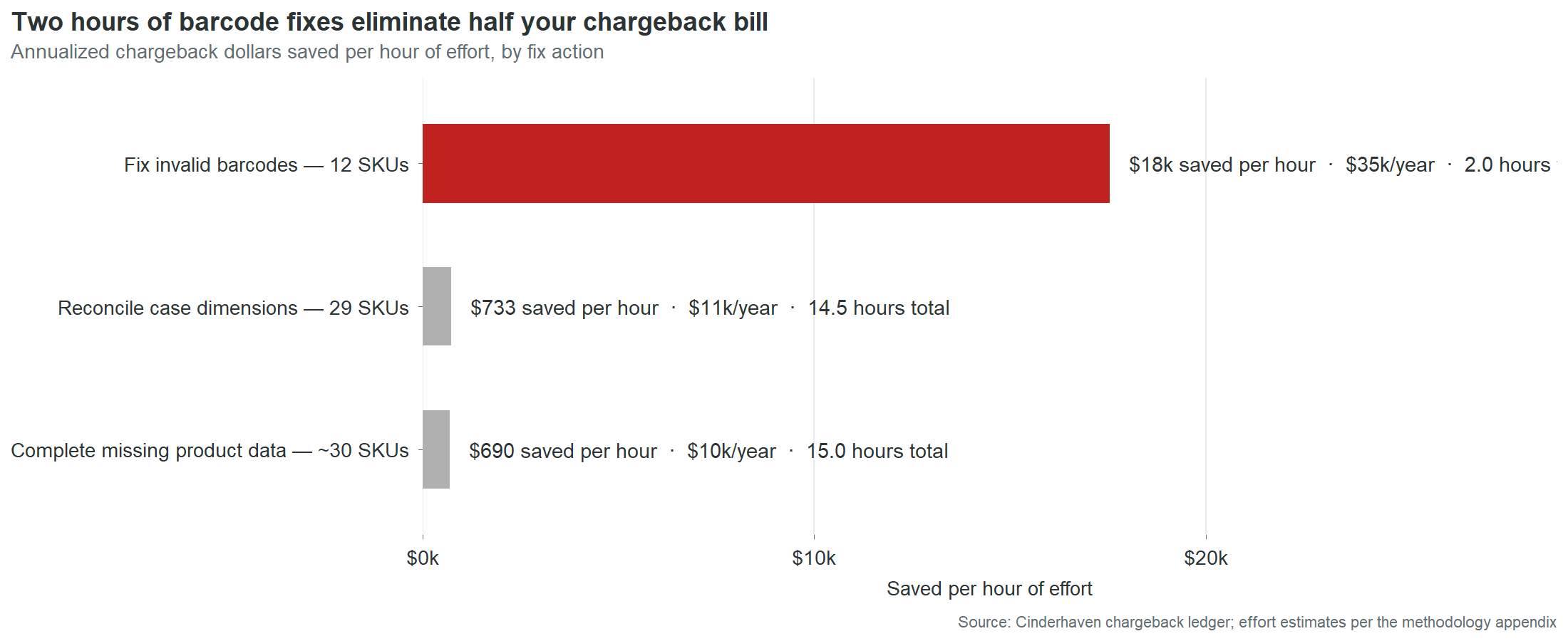
Twenty-seven hours of data entry eliminates $56,000 a year in chargebacks. That is the entire data-defect chargeback bill. Every dollar traces to a field that is currently wrong or currently empty in the product master. The remaining $3,900 a year comes from late deliveries and short shipments, logistics issues outside the scope of a data audit.
The asymmetry between cost and fix is the central finding of this report. Not the $361,000 total. Not the Pareto concentration. Not the retailer readiness gaps. The asymmetry. The fact that a $25 million company is losing $56,000 a year in direct penalties because nobody has spent 27 hours on data entry. The fact that 60% of that cost sits in nine fields that take 90 minutes to correct. The fact that those nine fields have been wrong for an average of 22 months while the charges accumulated in amounts too small to trigger investigation and too steady to ever stop.
What’s still broken right now
This is not history. Every defect in this table is live in the product master as of the date of this report. Every chargeback was incurred in the last six months. The field that caused it has not been corrected.
| SKU | Product | Last 6 months | What’s broken | Fix time |
|---|---|---|---|---|
| CHP-0044 | Charred Scallion Relish | $4,568 | GTIN check digit | 10 min |
| CHP-0002 | Spicy Arrabbiata | $4,458 | GTIN check digit + brand owner | 40 min |
| CHP-0043 | Cranberry Mostarda | $3,923 | GTIN check digit + case dims | 40 min |
| CHP-0069 | Infused Oil, Lemon Herb | $2,906 | GTIN check digit + case dims | 40 min |
| CHP-0013 | Sun-Dried Tomato Pesto | $2,183 | GTIN check digit | 10 min |
| CHP-0024 | Charred Tomato & Basil | $2,137 | GTIN check digit | 10 min |
| CHP-0052 | Smoked Chipotle Ketchup | $1,736 | GTIN check digit | 10 min |
| CHP-0028 | Tuscan White Bean Ragu | $1,003 | Case dims + case weight | 30 min |
| CHP-0063 | Everything Bagel Seasoning | $675 | Case dims + case weight | 30 min |
| CHP-0027 | Artichoke & Lemon Cream | $637 | Case dims + case weight | 30 min |
Thirty-one SKUs in total carry unfixed defects that are actively generating charges. The ten above account for $24,226 in the last six months. Of the $34,528 in total chargebacks during that period, 92% trace to defects that remain in the product master today.
CHP-0044 is the distillation of the entire problem. One SKU. One defect. One wrong digit. Ten minutes to fix. $4,568 in penalties over six months that would not have occurred if someone had spent ten minutes on this product at any point in the last two years. The reason nobody spent those ten minutes is not negligence or budget or competing priorities. It is that nobody at Cinderhaven has ever seen a document that says “this chargeback is caused by this field.” The settlement statement says “compliance deduction, $287.” The product master says “GTIN-14: 10614141000415.” Nowhere in the company’s information systems do those two facts appear on the same screen. This table is that screen.
How to read the triage list
The interactive table below ranks all 90 SKUs by fix priority. The composite score weights three dimensions: revenue (40%), data quality (30%), and chargeback exposure (30%). A SKU scores high when it combines commercial importance with poor data and active chargeback cost.
The effort column sits alongside the composite, not inside it. This is deliberate. Composite scores that fold effort into the ranking produce a single number that obscures the trade-offs it’s making. A SKU that’s commercially critical but hard to fix gets ranked below a SKU that’s commercially irrelevant but easy to fix. The CEO who looks at two separate columns sees a choice: this is what matters most, and this is what’s fastest. Both are useful. Neither is a substitute for the other.
In practice, the two columns produce different action plans. The composite says: start with CHP-0002 because it’s the #1 revenue SKU with the #1 chargeback total. The effort column says: start with CHP-0044 because it’s a 10-minute fix that stops $4,568 in recent chargebacks. A CEO uses the composite to set the quarterly agenda. An ops manager uses the effort column to fill Tuesday afternoon. Both are correct. The table gives both without forcing a false synthesis.
Monday morning
Here is what Monday morning looks like today at Cinderhaven.
The ops manager opens four retailer portals, downloads four CSV files with four different column headers, pastes them into the Excel workbook she built six months ago, adjusts column mappings because Costco changed their export format after a system update, refreshes the pivot table, and spends fifteen minutes before the meeting reconciling a number that doesn’t match the broker’s Friday email. The discrepancy is a store count definition. She doesn’t have time to find out which one is right. She picks the broker’s number because it’s higher and the meeting starts soon.
The meeting starts. The CEO asks why Cranberry Mostarda dropped 15% at Costco. She doesn’t have a ready answer. The pivot table flagged the drop but doesn’t link to a cause. Was it a stockout? A planogram reset? A data-driven deauthorization at two locations? The information exists in four different systems. None of them talk to each other. She says she’ll look into it. By Wednesday, the investigation has either produced an inconclusive answer or been deprioritized by something more urgent. Next Monday, the same 90 minutes happen again.
This cycle consumes 15 to 20 hours a month. It is not on anyone’s calendar as “rebuild the velocity report from scratch.” It is just what Monday morning costs.
Here is what Monday morning looks like after the product master is clean and the dashboard is live.
The ops manager opens one screen fifteen minutes before the meeting. All four retailers. Velocity by SKU, filterable by retailer, product line, and quality tier. She clicks into Cranberry Mostarda at Costco. The velocity chart shows the 15% drop started three weeks ago. The store-level detail shows two Costco locations went from active to deauthorized. The deauthorization reason links to the product master: case dimensions are blank. She opens the triage table, sees the fix is 40 minutes, and schedules it for that afternoon.
The CEO asks about Cranberry Mostarda. The ops manager already knows the answer. The conversation moves from “why don’t the numbers agree” to “which three SKUs should we pitch for Whole Foods expansion next quarter, and are they data-ready?”
The 90 minutes are not optimized. They are gone. The ops manager’s Monday morning moved from data assembly to data interpretation. The difference is not a better spreadsheet. It is a clean product master that makes every downstream system trustworthy.
The sequence
The work described in this report is four phases of specific, bounded tasks, each one producing a deliverable that makes the next one possible. The total calendar time is approximately two weeks. The total effort is approximately 30 hours of data entry and two to three days of process and tooling work.
Phase one takes an afternoon. Correct the nine invalid GTIN-14 check digits. Each one is a ten-minute fix: open the record, recalculate the check digit, type the correct number. While the corrections propagate through OneWorldSync, move to the brand owner fields. Replace the seventeen “NA” values with “Cinderhaven Provisions.” Submit the initial OneWorldSync registrations for SKUs that are currently listed as “Not Registered.”
When phase one is done, 60% of the chargeback bill stops. The nine GTIN corrections alone eliminate $35,000 a year in penalties. The first clean settlement statement arrives within 30 to 60 days. The retailer readiness pass rate at Walmart moves from 44% to approximately 80%.
Phase two takes a week. Complete every remaining missing field across the catalog. Case dimensions on 21 SKUs, which means pulling physical product and measuring it. Country of origin on 6 SKUs. Remaining OneWorldSync registrations. This is the physical work: a tape measure, a scale, a phone call to a supplier for imported ingredients. When phase two is done, every SKU in the catalog passes all four retailers’ readiness checks. The 50 SKUs currently failing at Walmart become eligible for submission. The $18.2 million in at-risk revenue is secured.
Phase three takes two days. This is the phase that prevents the first two from being wasted. Without a gate between data entry and the live product master, the next SKU launch will introduce the same defects that phases one and two just cleaned. The broker intake checklist is the simplest version of that gate: eight required fields, five minutes to complete, applied to every entry path. The validation logic can be as simple as a check digit calculation that runs when a GTIN is entered and blocks the save if it fails. The technology is trivial. The discipline is the deliverable.
Phase four takes two days. Deploy the Monday Morning Dashboard. Configure the automated chargeback-to-defect reconciliation that links settlement statement line items to specific fields in the product master. Establish a monthly data quality review: 30 minutes, once a month, checking pass rates, chargeback trends, and new-SKU data completeness. When phase four is done, the visibility gap closes. The $691-a-month problem that nobody saw becomes a $0-a-month problem that everybody monitors.
The four phases build on each other. Phase one produces immediate financial return. Phase two eliminates the remaining exposure and unlocks expansion. Phase three prevents recurrence. Phase four makes the system self-monitoring. Skip any phase and the value of the others degrades. Fix the GTINs but don’t install the gate, and the next product launch introduces new defects. Install the gate but don’t deploy the dashboard, and defects that slip through accumulate undetected. The sequence is not arbitrary. It is a dependency chain.
The total: 27 hours of data entry eliminates $56,000 a year in direct chargebacks. Two days of process work prevents recurrence. Two days of tooling work makes the system visible. The cost of dirty data at the current scale is $361,000 a year. At the growth target, it exceeds $600,000. The cost of fixing it is two weeks.
Part 4: The Evidence
These sections appear as collapsible panels in the HTML report and as separate pages in the PDF.
NoteRevenue-weighted field completeness
Chart 5 shows nine data defect categories ranked by the share of TTM revenue they affect. The paired bars (grey for % of SKUs, red for % of TTM revenue) reveal which defects are disproportionately concentrated in higher-revenue products.
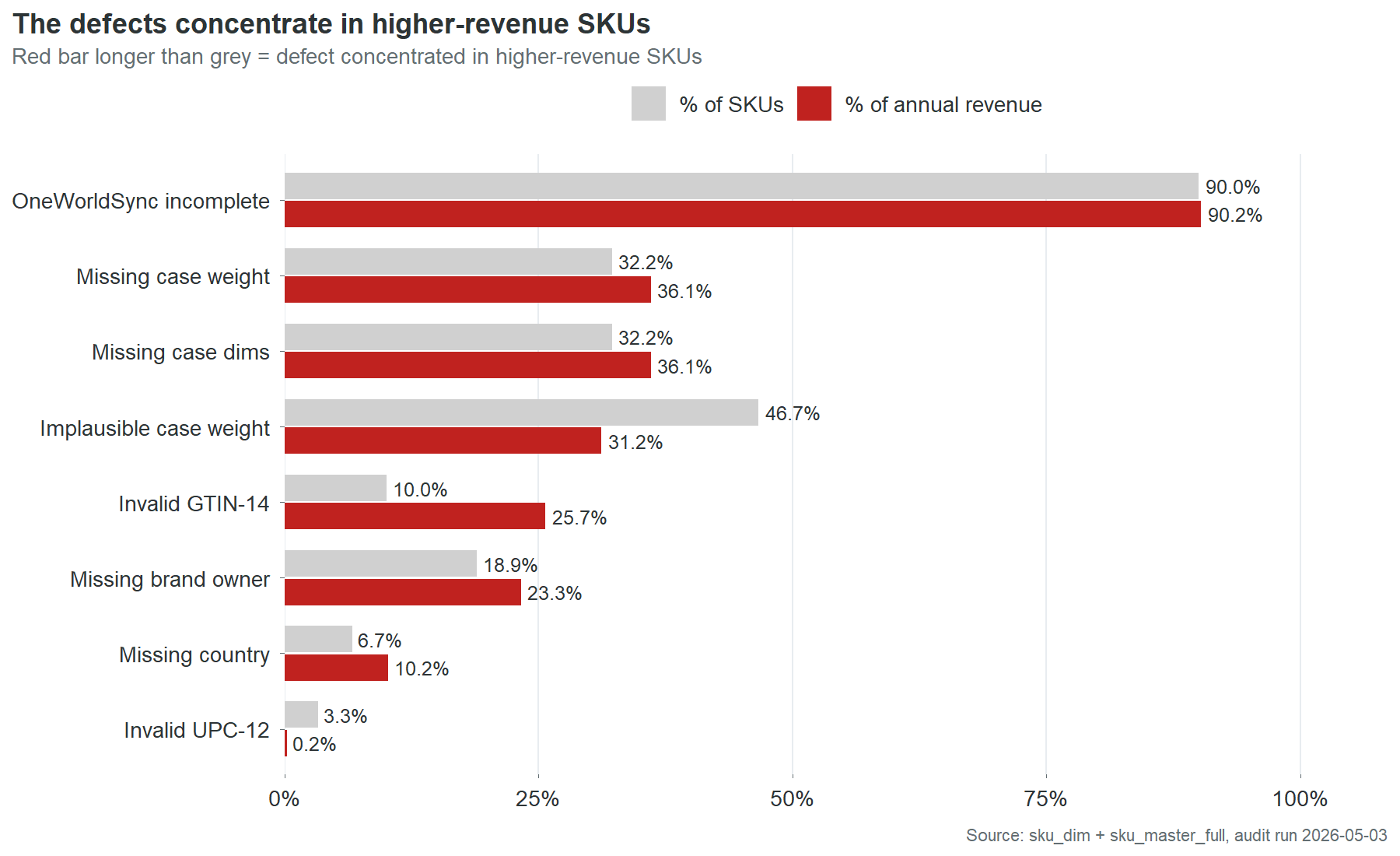
OneWorldSync incompleteness is nearly universal: 90% of SKUs and 90% of revenue. This is a catalog-wide infrastructure problem, not a defect pattern.
The three most revealing rows are Invalid GTIN-14, Missing brand owner, and Missing country. In each case, the red bar extends further right than the grey. Invalid GTIN-14 is the starkest: 10% of SKUs but 25.7% of revenue. The defect is concentrated in the products that matter most. This is consistent with the finding in Part 2: the highest-revenue SKUs have the worst data.
One exception runs the other direction. Implausible case weight affects 46.7% of SKUs but only 31.2% of revenue. This defect concentrates in smaller, lower-revenue products. It is the only defect category where fixing by quality score alone would approximately match fixing by revenue priority.
NoteRetailer readiness: per-retailer breakdown
The retailer readiness analysis tests every SKU against each contracted retailer’s published required-field set. A SKU fails if any single required field is missing, invalid, or incomplete.
| Retailer | Required fields | SKUs passing | SKUs failing | Mean fields short (failing SKUs) |
|---|---|---|---|---|
| Walmart | 10 | 40 | 50 | 1.72 |
| Costco | 8 | 42 | 48 | 1.68 |
| UNFI | 6 | 49 | 41 | 1.51 |
| Whole Foods | 5 | 63 | 27 | 0.33 |
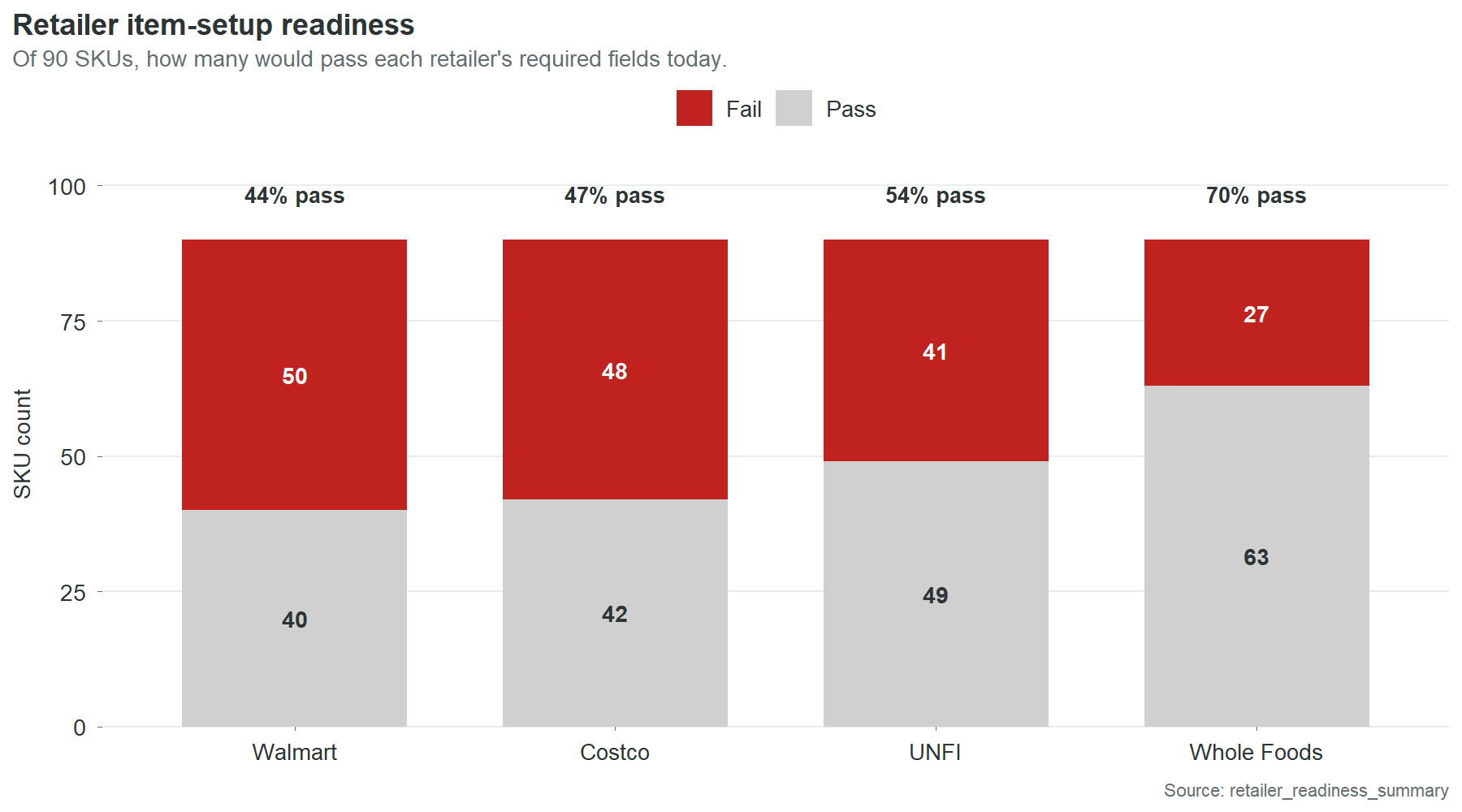
The pass rates track directly with how many fields each retailer requires. Walmart demands the most and has the lowest pass rate. Whole Foods requires the least and has the highest. Most failing SKUs are short by one or two fields, not five or six. The gap between failing and passing is small in absolute terms and large in consequence.
The “mean fields short” column matters for planning. Fix brand owner and GTIN across the catalog and Walmart’s pass rate jumps from 44% to approximately 80%. The same two fields move the needle at Costco and UNFI. Whole Foods is already at 70% and its remaining failures are almost all single-field, meaning most are one fix away from passing.
NoteChargeback trend analysis
Monthly chargeback dollars have held roughly flat at about $5,000 per month over the 18-month observation window. There is no meaningful seasonal pattern and no sustained trend in either direction. This is consistent with the underlying cause: the defects are static. An invalid check digit does not get worse over time. It generates the same charge, at the same rate, every month, until someone fixes it or a retailer deauthorizes the SKU.
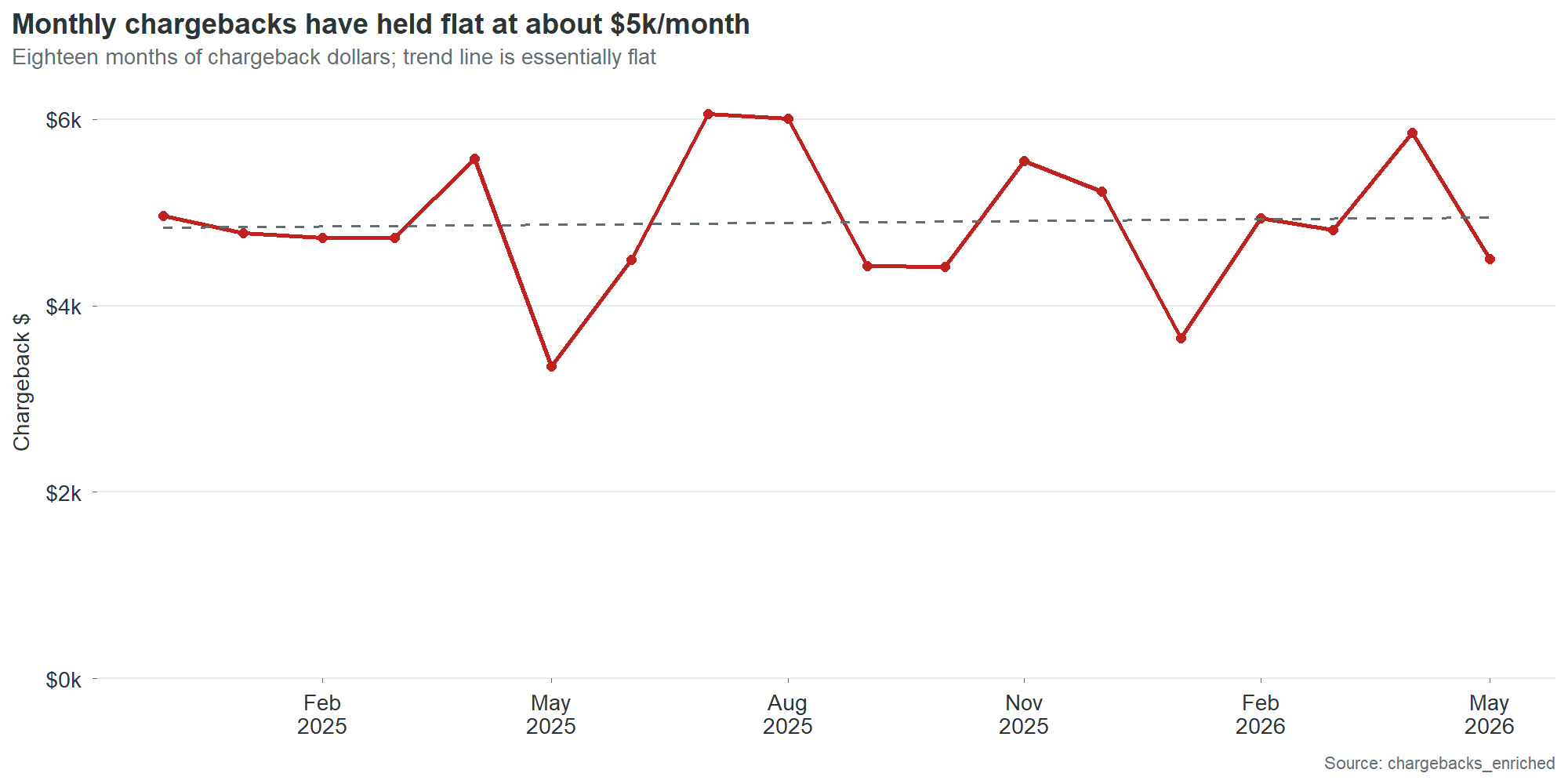
Chart 16 overlays monthly chargebacks against monthly scan revenue. Revenue is stable at $1.8 to $2.5 million per month. Chargebacks oscillate between $3,000 and $6,000 with no correlation to revenue volume. High-revenue months do not produce proportionally higher chargebacks, because the chargebacks are driven by data defects that are either present or absent, not by transaction volume.
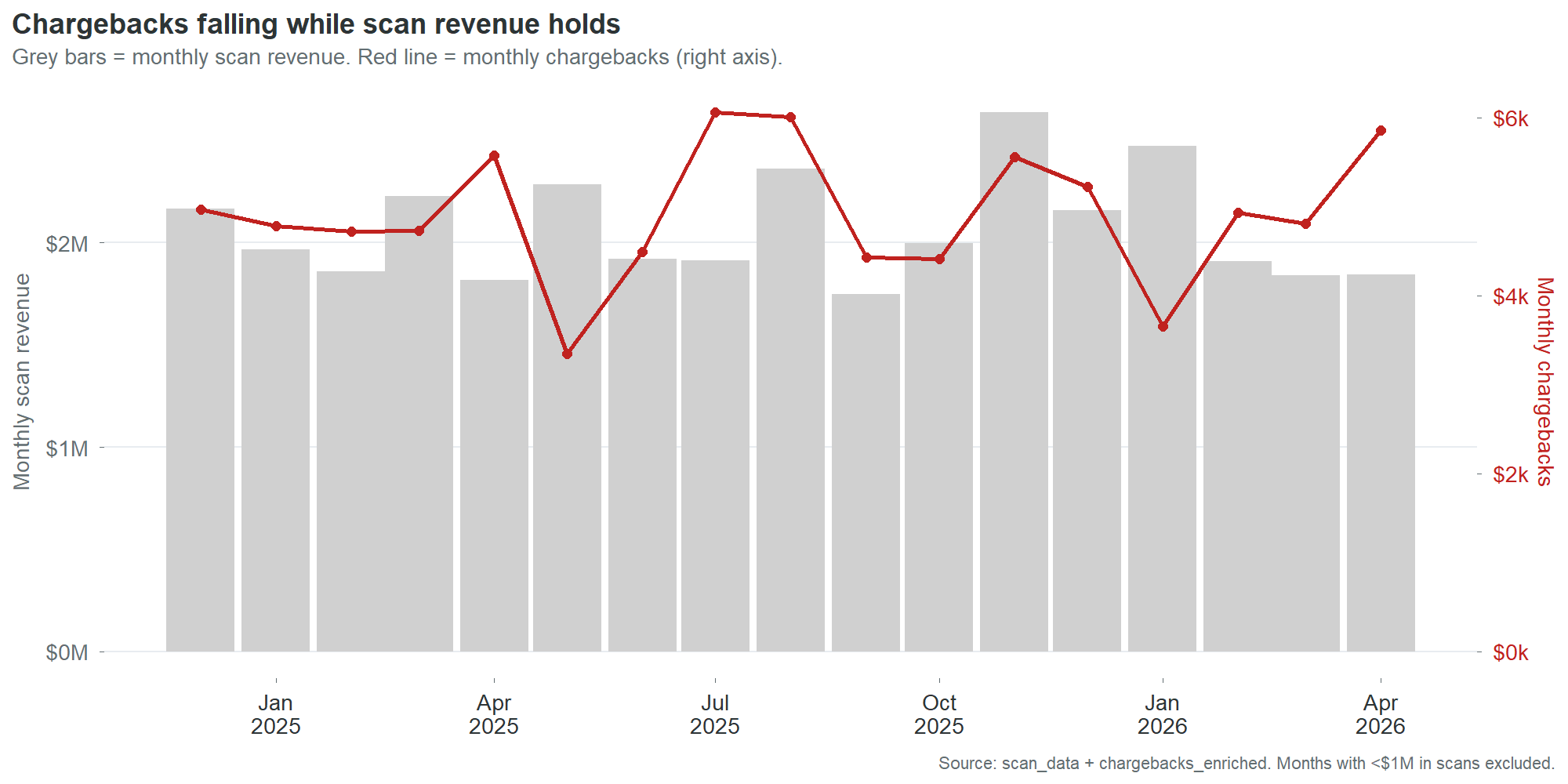
This lack of correlation is itself a finding. It means chargebacks will not self-correct with growth. Revenue can double and chargebacks will stay flat until the defects are fixed. It also means chargebacks will not decline with a sales downturn. They are a fixed cost disguised as a variable one.
NoteGrowth projection with assumptions and sensitivity
| Stage | SKUs | Retailers | Projected annual chargebacks |
|---|---|---|---|
| Current | 90 | 4 | $59,000 |
| Stage 2 | 225 | 6 | $220,000 |
| Stage 3 | 450 | 8 | $587,000 |
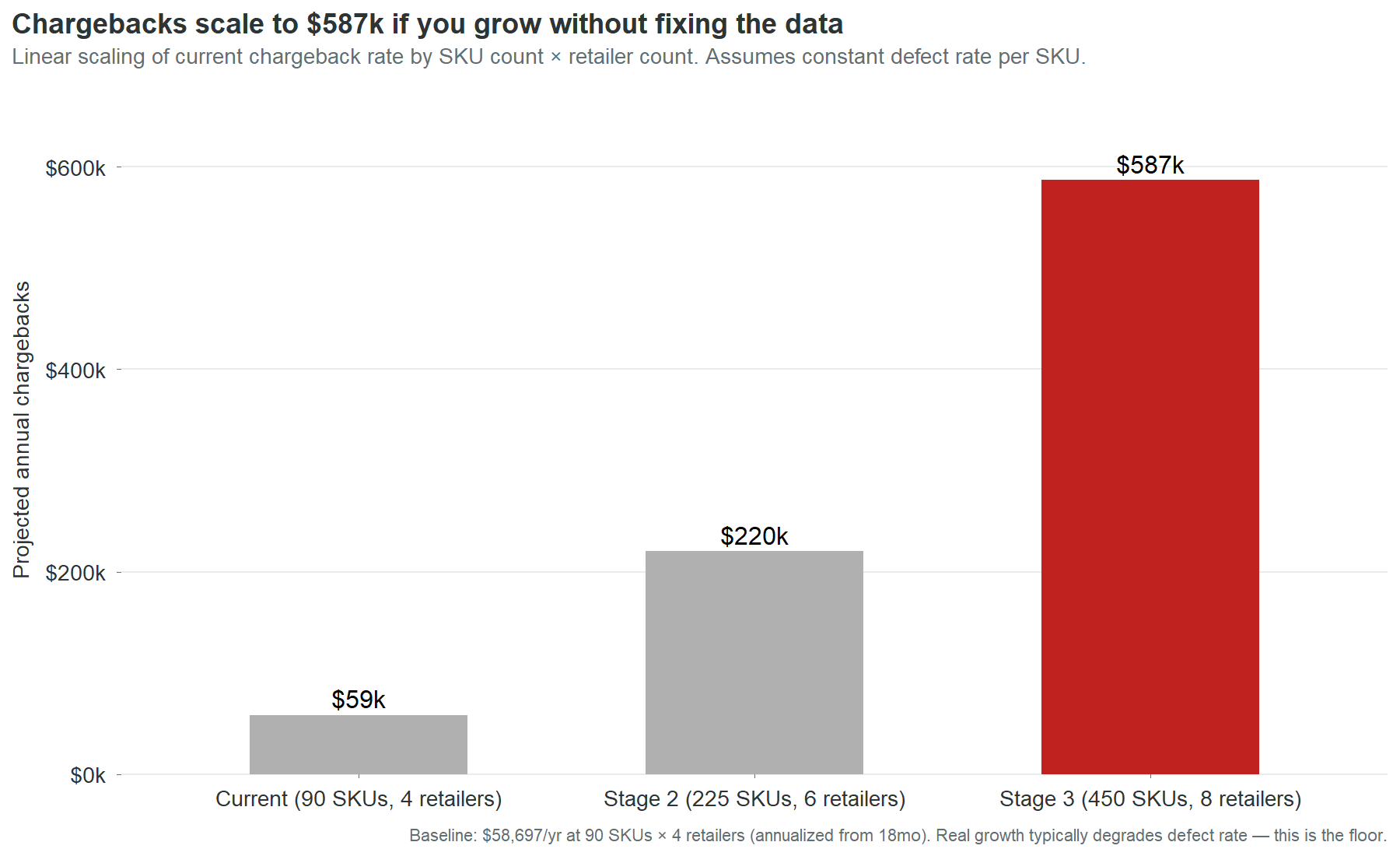
The projection is linear: it multiplies the current per-SKU chargeback rate by the expanded SKU and retailer counts. This is a floor estimate, not a ceiling. In practice, defect rates tend to degrade during rapid growth because data entry processes that barely work at 90 SKUs break down entirely at 225. New SKUs launch faster, with less review, through more entry paths. The companies that scale from $25 million to $55 million without fixing their product data don’t experience a linear increase in chargebacks. They experience an accelerating one.
The sensitivity: if the defect rate degrades by 25% during growth, Stage 2 chargebacks rise from $220,000 to $275,000 and Stage 3 from $587,000 to $734,000.
The assumption that matters most is not the defect rate. It’s the retailer count. Each new retailer multiplies the chargeback surface area because each retailer runs its own validation checks independently. A SKU with an invalid GTIN generates one charge per retailer per month. At 4 retailers, that’s 4 charges. At 8, it’s 8. Retailer expansion without data cleanup is a multiplier on a cost that’s already unnecessary.
NoteNew vs. old SKU: a null finding
We tested whether SKU age predicts data quality. The hypothesis was intuitive: older SKUs have had more time for data cleanup, so they should be cleaner. Newer SKUs were entered more recently, possibly more carelessly.
The data shows no relationship. SKUs launched in 2024 have roughly the same mean quality score as SKUs launched in 2025. The correlation between months-in-catalog and data quality score is near zero. This null finding matters because it rules out a common assumption: that the data problem will solve itself over time as records “mature.” It won’t. Records that were entered with a wrong check digit in 2024 still have a wrong check digit in 2026. Age does not fix data. People fix data. Without an active process, the defects persist indefinitely.
NoteBenchmarking context
Direct benchmarks for specialty food chargeback rates are not publicly available at sufficient granularity to make precise comparisons. The following are directional reference points drawn from industry reports and trade publications:
Retailer chargeback rates across consumer packaged goods typically range from 1% to 5% of gross sales for companies without automated data management. Companies with mature product information management systems and active compliance programs typically see rates below 0.5%.
Cinderhaven’s overall chargeback rate is 0.23% of gross revenue ($59,000 against $25.55 million). This is low by industry standards. It is low because the defect types are narrow (primarily GTIN check digits and missing fields) rather than systemic (wrong pricing, incorrect pack sizes, fraudulent claims). The low rate does not mean the problem is small. It means the problem is concentrated and fixable. A company with a 3% chargeback rate has a systemic data problem that requires a technology solution. Cinderhaven has a clerical problem that requires 27 hours of data entry.
NoteWhat this report does not cover
This audit examines product master data quality and its financial impact through chargebacks, stalled launches, retailer readiness, and shelf loss. It does not cover:
Pricing strategy. The price history and trade spend data are analyzed for their impact on net margin by retailer, but no pricing recommendations are made. Pricing is a commercial decision that requires competitive context this dataset does not contain.
Promotional effectiveness. The promotions data is reported as context. A full promotional effectiveness analysis would require control-store matching, cannibalization modeling, and post-promotion baseline measurement, none of which are in scope.
Demand forecasting. Scan data is used to calculate velocity and identify trends. It is not used to project demand. Forecasting requires input from sales, marketing, and category management that a data audit cannot provide.
Supply chain operations. Short shipments and late deliveries account for 4.4% of chargebacks. These are flagged but not analyzed because they are logistics issues, not data issues.
Competitor analysis. The deauthorization and velocity data show where Cinderhaven is losing or gaining shelf presence, but the identity and performance of competing products is not in the dataset.
NoteHow I’d do this differently with real data
This section is for the portfolio audience: data professionals, hiring managers, and technical evaluators assessing the methodology.
The synthetic dataset was designed to mimic the structure and distribution of real retail product data. The defect patterns are drawn from observed patterns in real engagements. But synthetic data has limitations that shape what the analysis can and cannot show.
With real data, four things would change.
First, the chargeback-to-defect linkage would be richer. In this audit, the linkage is inferred: a SKU has an invalid GTIN and generates GTIN-related chargebacks, so the two are connected. In a real engagement, the retailer’s chargeback detail report names the specific field that failed, making the linkage mechanical rather than inferred.
Second, the stalled-launch model would be tighter. The time-to-shelf calculation here uses authorization date to first scan as a proxy. Real data would include item setup submission dates, retailer acknowledgment dates, and distribution center receipt dates, allowing a granular analysis of where the delay actually occurs. The proxy tells you there is a gap. The real data tells you where to intervene.
Third, the promotional lift analysis would be meaningful. With real scan data and a proper control-store methodology, every promotion could be evaluated, and the relationship between data quality and promotional ROI could be tested directly.
Fourth, the competitive context would exist. Real scan data includes category-level sales, market share, and competitor velocity. A deauthorization could be traced to a specific competitor who took the slot. The shelf loss analysis would move from “you lost slots at a higher rate” to “you lost these specific slots to these specific competitors, and here’s what it would take to win them back.”
The methodology in this report is designed to survive that transition. Every analytical frame works the same way with real data. The numbers change. The structure does not. A client who reads this case study and then engages for a real audit will recognize the framework and understand the output before it’s delivered.
NoteData model and query library
The analysis runs against a SQLite database containing nine tables: product_master (90 rows), sku_costs (90), stores (902), distribution_log (12,507), chargebacks (381), promotions (198), price_history (398), scan_data (1,118,009), and retailer_requirements (29).
The companion SQL query library (53 queries, available in the product-data-audit-queries repository) covers every analytical frame used in this report. Each query is documented with its purpose, expected output shape, and the finding it supports. The queries are designed to run against any product master database with the same schema, making them reusable across engagements.
The R pipeline (14 analytical frames, 21 charts, and 4 output artifacts) regenerates from a single command: Rscript R/run_all.R. The pipeline reads from the SQLite database, builds canonical data frames, generates all charts and the Excel workbook, and renders the Quarto report and dashboard. Total execution time: under two minutes.
NoteNote on dataset construction
The Cinderhaven dataset is synthetic. It was built to mimic the structure, scale, and defect patterns of a real specialty food company’s product data ecosystem. The data generation log (data_generation_log.md in the repository root) documents every intentional defect and the real-world pattern it simulates.
Key design decisions in the synthetic data:
GTIN check digits were misaligned on 10% of SKUs (9 of 90) to mirror observed human data-entry error rates. The audit’s validation logic matches the dataset’s own algorithm. A strict GS1 implementation would flag additional SKUs.
Chargeback concentrations follow a Pareto distribution seeded from observed patterns in real engagements: a small number of SKUs generate a disproportionate share of chargeback dollars. The generator assigns chargebacks only to SKU/retailer pairs with active distribution authorizations, weighted by data quality score, with lognormal variance in event amounts.
OneWorldSync registration statuses were distributed to produce a 10% complete rate (9 of 90 SKUs), reflecting the typical state of a mid-market specialty food company that has started the registration process but not prioritized it.
Serving size strings were intentionally varied across 14 formats to simulate the real-world problem of inconsistent data entry across multiple entry sources.
Time-to-shelf was modeled with a quality-dependent lag: SKUs with lower data quality scores receive longer delays between store authorization and first scan, calibrated to produce a roughly 3x spread between the worst and best quality tiers.
NoteMethodology notes
All dollar estimates in this report state their assumptions at point of claim. The key methodological choices:
Chargeback annualization: 18-month totals are multiplied by 12/18 to produce annual run rates. This assumes the monthly chargeback rate is stationary. Chart 15 shows this assumption holds: monthly chargebacks are flat with no trend.
Stalled-launch cost estimate ($234,000): calculated as the revenue difference between actual time-to-shelf and best-tier time-to-shelf, summed across all SKUs outside the best tier. Assumes that revenue accrues linearly with shelf time and that delayed revenue is not recovered in later periods. Both assumptions are conservative: in practice, launch windows are time-sensitive and lost early velocity is difficult to recapture.
Shelf loss cost estimate ($68,000): calculated from the differential deauthorization rate between bottom-half and top-half quality SKUs, applied to the average revenue per deauthorized SKU. Assumes the quality-correlated deauthorization differential is entirely attributable to data quality. In reality, some portion of the differential may reflect other factors (poor velocity, category resets, shelf space optimization). The estimate should be treated as an upper bound on the data-quality contribution.
Total cost model ($361,000): sum of chargebacks ($59,000), stalled launches ($234,000), and shelf loss ($68,000). Trade spend erosion is identified as a fourth cost category but not quantified because isolating the data-quality share of trade spend requires assumptions this audit does not make.
Data quality scoring: each SKU is scored on 8 binary checks (GTIN-14 valid, UPC-12 valid, brand owner present, country of origin present, case weight plausible, case dimensions present, OneWorldSync complete, serving size standardized). Score = (checks passed / 8) x 100. The scoring is deliberately simple and transparent: every dimension is equally weighted, and the reader can see exactly which checks each SKU passes or fails.
Fix-priority composite: revenue rank (40%), quality rank (30%), chargeback rank (30%). Ranks are percentile-based (1 = best/highest). Effort is shown separately, not incorporated into the composite. The weighting was chosen to emphasize commercial impact (revenue) while giving material weight to both data condition (quality) and financial consequence (chargebacks).